Overview#
Overview#
The Open Data Cube is a collection of software designed to:
Manage large amounts of Earth observation data, either stored on a file system or a cloud platform
Provide a Python based API for high performance querying and data access
Give scientists and other users easy ability to perform exploratory data analysis
Allow continental-scale processing of the managed data
Track the provenance of all managed data to allow for quality control and updates
The Open Data Cube software is based around the datacube-core library. In addition to this core library, there are a range of tools that can be installed on top to enable further capabilities, such as open web services or metadata exploration.
All software in the Open Data Cube project family is released under the Apache 2.0 license.
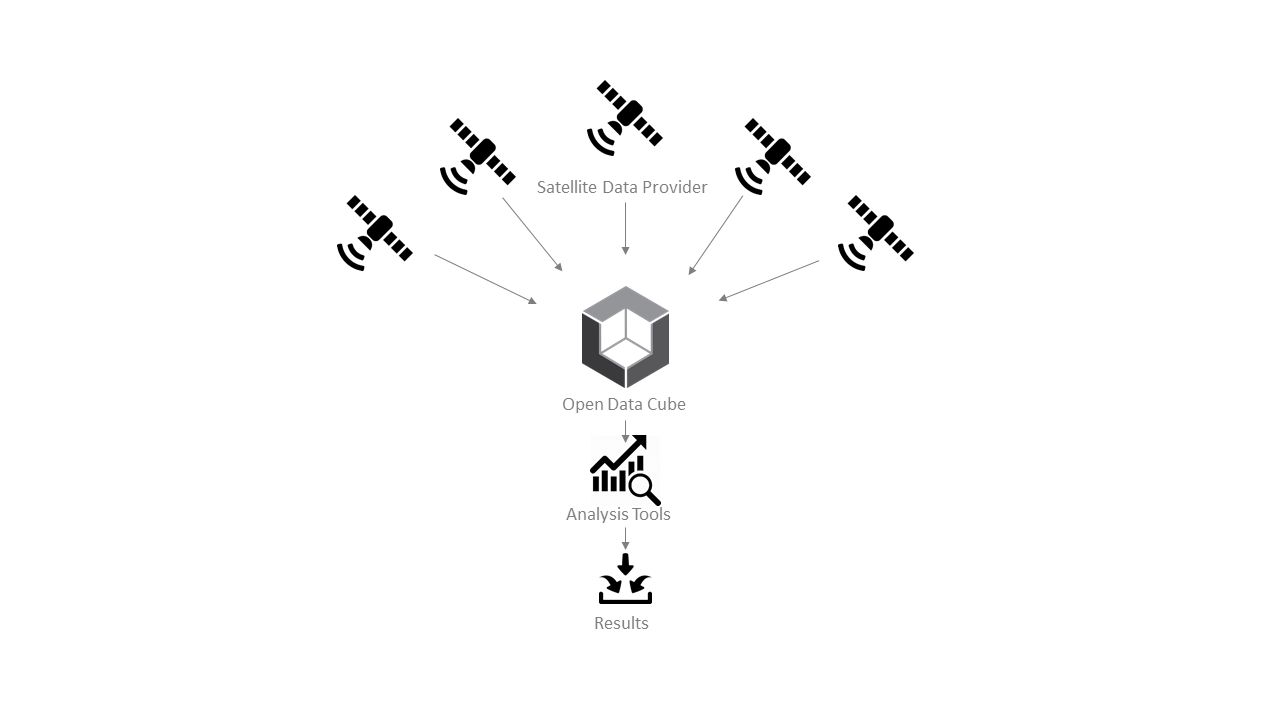
Fig. 1 High-Level ODC Overview#
Use Cases#
The Open Data Cube has a range of uses, including the following:
Collection Management: The ODC can be used as an index to assist in managing a collection of Earth observation data, including lineage (parent/child relationships).
Exploratory Data Analysis: Interactive analysis of data, such as through a Jupyter Notebook.
Publishing Web Services: Using the ODC to serve WMS, WCS, WPS or custom tools (such as polygon drill time series analysis).
Large-scale workflows on Cloud: Continental or global-scale processing of data on the cloud using XArray and Dask on Kubernetes, for example.
Large-scale workflows on HPC: Continental or global-scale processing of data on a High Performance Computing supercomputer cluster.
Standalone Applications: Running environmental analysis applications on a laptop, suitable for field work, or outreach to a developing region.
The Open Data Cube Software Ecosystem#
The Open Data Cube software ecosystem enables people to manage and process Earth observation data. It is made up of a number of Python packages, which are described in the The Open Data Cube Ecosystem section.
About & Core Concepts
Managing Data
Working With Data
The ODC Packages and Deployments