Ingesting Data#
Note
Ingestion is no longer recommended. While it was used as an optimised on-disk storage mechanism, there are a range of reasons why this is no longer ideal. For example, the emergence of cloud optimised storage formats means that software such as GDAL and Rasterio are optimised for reading many files over the network. Additionally, the limitation of NetCDF reading to a single thread means that reading from .TIF files on disk could be faster in some situations.
In addition to limited performance improvements, ingestion leads to duplication of data and opinionated decisions, such as reprojection of data, which can lead to a loss of data fidelity.
The section below is being retained for completion, but should be considered optional.
Congratulations, you’re ready to ingest some data. If you’ve made it this far you should already have some data indexed, and want to tile it up into a faster storage format or projection system.
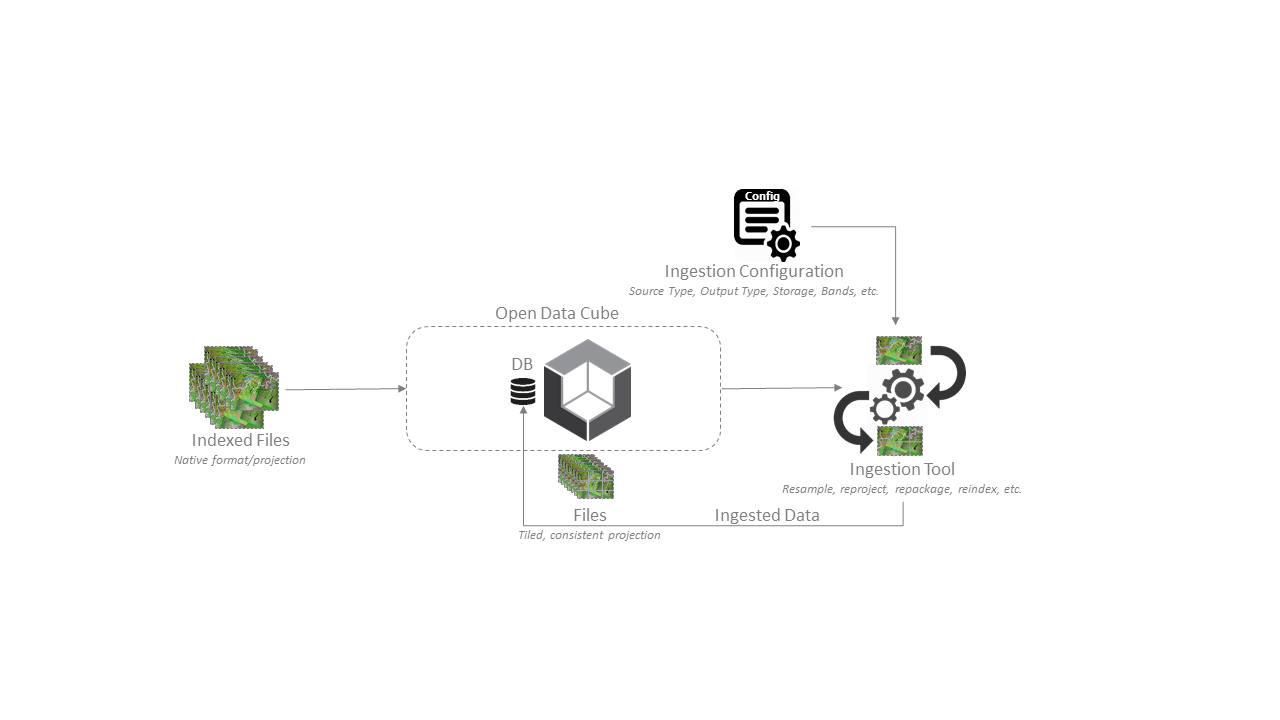
Ingestion Configuration#
An Ingestion Configuration file defines a mapping from the way one set of Datasets is stored, into a new storage scheme for the data. This will be recorded in the index as a new product, and the data will be manipulated and written out to disk in the new format.
An Ingestion Config is written in YAML and contains the following:
which measurements are stored
what projection the data is stored in
what resolution the data is stored in
how data is tiled
where the data is stored
how the data should be resampled and compressed
Multiple ingestion configurations can be kept around to ingest datasets into different projections, resolutions, etc.
Ingestion Config#
An ingestion config is a document which defines the way data should be prepared for high performance access. This can include slicing the data into regular chunks, reprojecting into to the desired projection and compressing the data.
An Ingestion Config is written in YAML and contains the following:
Source Product name -
source_typeOutput Product name -
output_typeOutput file location and file name template
Global metadata attributes
Storage format, specifying:
Driver
Resolution
Tile size
Tile Origin
Details about measurements:
Output measurement name
Source measurement name
Resampling method
Data type
Compression options
- output_type
Name of the output Product. It’s used as a human-readable identifer. Must be unique and consist of alphanumeric characters and/or underscores.
- description (optional)
A human-readable description of the output Product.
- location
Directory to write the output storage units.
- file_path_template
File path pattern defining the name of the storage unit files. TODO: list available substitutions
- global_attributes
File level (NetCDF) attributes
- storage
- driver
Storage type format. Currently only ‘NetCDF CF’ is supported
- crs
Definition of the output coordinate reference system for the data to be stored in. May be specified as an EPSG code or WKT.
- tile_size
Size of the tiles for the data to be stored in specified in projection units. Use
latitudeandlongitudeif the projection is geographic, otherwise usexandy- origin
Coordinates of the bottom-left or top-left corner of the (0,0) tile specified in projection units. If coordinates are for top-left corner, ensure that the
latitudeorydimension oftile_sizeis negative so tile indexes count downward. Uselatitudeandlongitudeif the projection is geographic, otherwise usexandy- resolution
Resolution for the data to be stored in specified in projection units. Negative values flip the axis. Use
latitudeandlongitudeif the projection is geographic, otherwise usexandy- chunking
Size of the internal NetCDF chunks in ‘pixels’.
- dimension_order
Order of the dimensions for the data to be stored in. Use
latitudeandlongitudeif the projection is geographic, otherwise usexandy. TODO: currently ignored. Is it really needed?
- measurements
Mapping of the input measurement names as specified in the dataset-metadata-doc to the per-measurement ingestion parameters
- dtype
Data type to store the data in. One of (u)int(8,16,32,64), float32, float64
- resampling_method
Resampling method. One of nearest, cubic, bilinear, cubic_spline, lanczos, average.
- name
Name of the NetCDF variable to store the data in.
- nodata (optional)
No data value
Ingest Some Data#
A command line tool is used to ingest data
Configuration samples are available as part of the open source Github repository.